深入分析多线程计算平台的性能模型
在前几篇文章中,作者谈到了单核CPU在PC和服务器上已经基本退出历史舞台的事实。目前主流的计算平台是多核CPU和多核GPU。此外,处理器和内存之间的速度差距越来越大,因此有两种方法可以克服内存访问的瓶颈。
多核CPU和单核CPU都使用Cache来掩盖访问系统内存的延迟,以此来降低访问内存带宽的压力,他们的芯片更大的面积也对Cache有贡献。另一端,GPU通过同时运行多个简单线程,不使用或者只使用相对较小的Cache。
而内存访问延迟主要由线程级并行(TLP)隐藏。当一些线程由于内存访问而停滞时,其他线程会继续执行,这样处理单元就不会空闲。
目前异构计算平台同时采用这两种不同的架构,性能难以预测和优化。面对给定的计算负载,应该如何分配才能达到最佳性能?对于芯片架构师来说,如何在面积有限的芯片上合理部署处理单元、寄存器堆和Cache也是一个头疼的问题。
为了给理解优化性能提供参考,作者定义了一个统一的仿真模型,该模型能够适应具有这两种不同特性的体系结构设计。这个模型对应一个假想的混合计算平台,由许多简单的处理单元和一个大型共享缓存组成。通过灵活配置一系列参数,包括处理单元数量、缓存大小以及缓存和内存的访问延迟,可以观察不同参数对计算性能的影响。
为了保持模型简单,本文假设所有线程不互相共享数据,并且系统内存带宽足够大。如下图所示,作者发现当线程数较少时,性能开始随着线程数的增加而提高,但当线程数达到一个转折点,Cache无法容纳所有线程的工作集时,性能反而下降。
之后随着线程数量的增加,由于有足够的线程来掩盖Cache访问未命中造成的内存访问延迟,性能再次上升,达到平台可以获得的最大性能。我们可以认为MC区域对应多核CPU的情况,而MT区域自然对应超级多线程GPU。在我们的体系结构设计和程序优化中,应该避免大规模定制区域和小规模定制区域之间的性能低谷区域。
下面,我们推导出参数曲线对应的公式。下表列出了计算模型中涉及的参数。左边是平台相关,右边是操作任务相关。
公式(1)是线程访问内存所需的平均时钟数,考虑了缓存命中率。
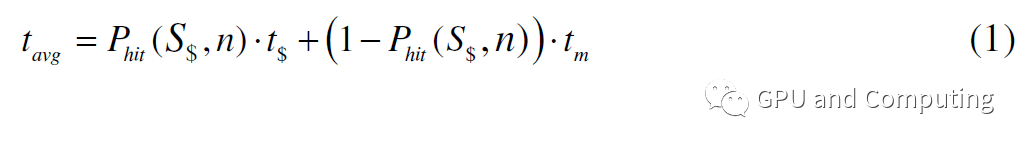
也就是说,每次线程运行1/rm指令,tavg时钟都会因为内存访问而停滞。如果没有其他线程被替换,相应的处理单元将处于空闲状态。为了充分利用这个处理单元,需要的额外线程数是tavg/(CPIexe/rm)。因此,为了使整个计算平台满负荷运行,所需的线程总数为
NPE * (1 tavg/(CPIexe/rm)).给定n个线程的计算任务,计算平台的利用率可以用公式(2)计算。
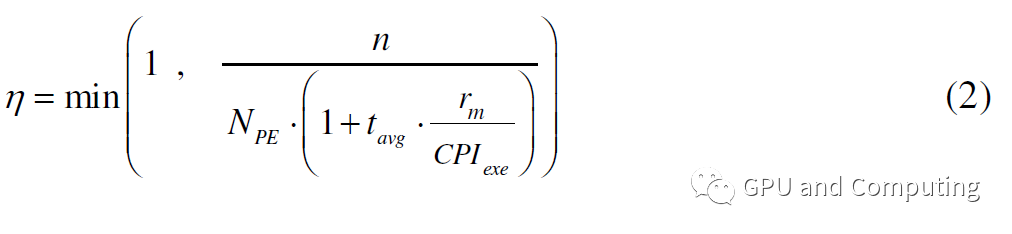
当=1时,增加额外的线程对性能没有帮助。根据利用率,我们可以得到计算平台的预期性能为npe * (f/CPI exe) * ops(每秒操作数)。通过这个公式,我们可以观察到以下参数对性能曲线的影响。
值得注意的是,我们在上面的计算中没有考虑有限的内存带宽。如果考虑到这一点,我们可以根据公式(3)计算特定性能所需的带宽。
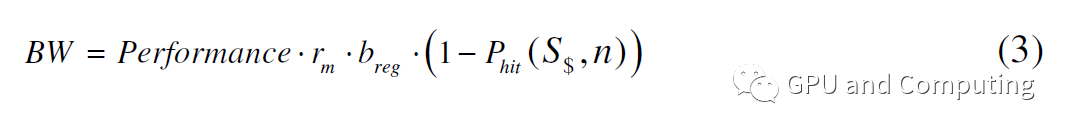
因此,当存储器带宽也是约束条件时,性能计算被修改为公式(4)。
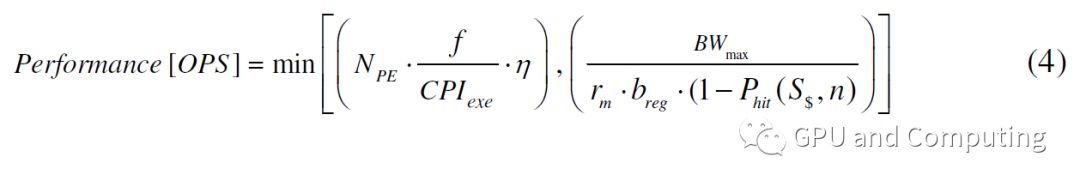
下图也反映了内存带宽对性能曲线的影响。值得提醒的是,性能曲线的顶层表示计算任务已经撞上了这个平台的片外带宽墙。在这种情况下,增加线程数可能会使Cache命中率恶化,使带宽问题更严重,但会削弱性能,这也是前面提到的GPU视频内存带宽远大于CPU系统内存带宽的原因。
主要参考资料:
众核vs众线程机器:远离山谷
片上多处理器中高速缓存和线程的相互作用
编辑:jq
延伸 · 阅读
- 2021-06-28 17:35苹果想摆脱对高通的依赖?
- 2021-06-28 17:35Wi-Fi 6和Wi-Fi 6E的优势和使用案例
- 2021-06-28 17:35在无铅锡膏中加入银的主要原因有哪些
- 2021-06-28 17:35十大热门CPU排名
- 2021-06-28 17:35苹果在印度高端手机市场占55%份额
- 2021-06-28 17:35lm311引脚图和功能












