华为发布了业内最大的2D自动驾驶数据集 是Waymo的10倍
当人类驾驶员驾驶汽车时,当他驾驶更多陌生的道路时,他将变得熟练。
自动驾驶需要大量的学习和训练。
这离不开提供庞大的数据集“训练场”和资料。
此前,Waymo拥有最大的2D自动驾驶数据集。
但现在,华为诺亚方舟实验室和中山大学发布了新一代2D自动驾驶数据集SODA10M。

比Waymo现有的大十倍。
包括1000万张未标注图片和2万张标注图片。
这个数据集除了大,还有什么区别?
数据集从何而来?
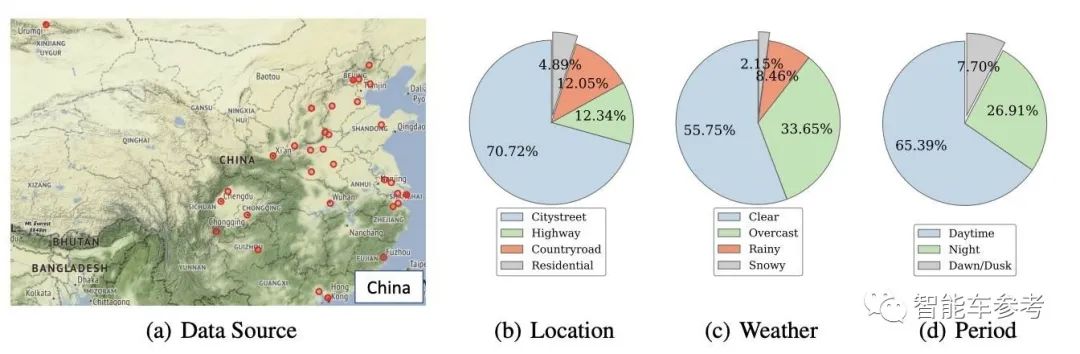
SODA10M数据集收集不同城市在不同天气条件、时间段和地点的场景。
晴天雨天,白天黑夜,城市高速公园.
更重要的是,覆盖面非常广。
千万张无标记图片来自32个城市,覆盖中国大部分地区。
20,000张带有标签的图片直接标记了六大类人和车辆,即:
行人、骑自行车的人、汽车、卡车、电车、三轮车。
具体是怎么操作的?
华为通过众包的方式,将催收任务分发给数万名出租车司机。
出租车司机用手机或行车记录仪(1080P)采集图片。
你觉得你能照张相吗?

还需要在不同的天气条件下,以每10秒一帧的速度采集图像。
地平线需要保持在图像中心,车内遮挡不能超过15%。
将随机选择5%的接收图像进行手动验证。
合格率低于95%的,退回。
与隐私相关的信息,比如人脸、车牌等,都会模糊不清。
最大的数据集有什么用?
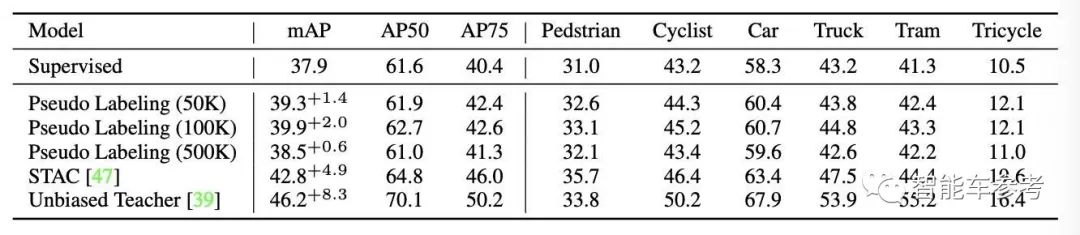
华为用贴了标签的训练集(2万张贴了标签的图片)为自动驾驶的主流模式打造了一场大pk。

对象是完全监督、半监督和自监督学习。
分为培训、验证和测试三个环节。
为了增加难度,最终测试选择的图片是上海的晴天和城市场景。
在验证的过程中,不同场景的图片很多。
最终结果表明,仅通过全监督训练训练的模型是无效的,并且全监督训练的精度与日间训练相差甚远。
此外,华为还带来了Waymo自动驾驶数据集和现有经典自监测算法数据集ImageNet,与SODA10M的性能进行对比。
从这三项开始:
1.目标检测;
2.BDD100K(伯克利发布的大型开放式驾驶视频数据集);
3.城市景观的语义分割。
效果如何?
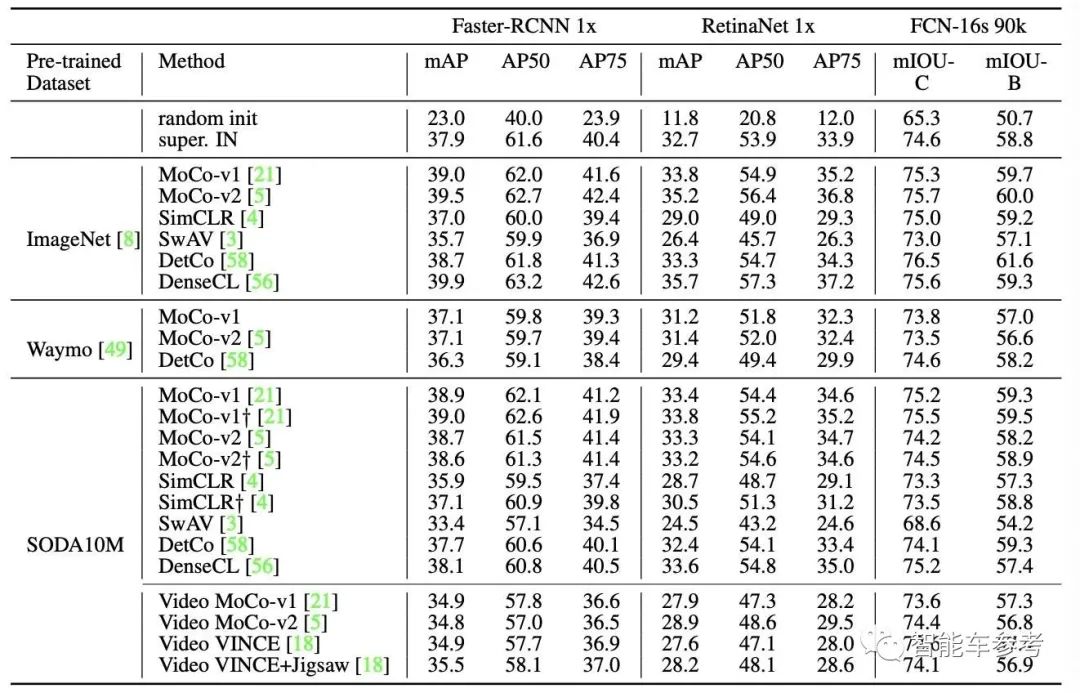
在基于像素和中间层特征的Moco系列(城市景观语义分割)和自监测方法DetCo、DenseCL上,SODA10M自监测训练的效果与ImageNet类似。
两者明显优于Waymo。

这也意味着自监督算法上游的数据集大小,对于下游的学习和测试有极大影响.
据华为介绍,这个数据集的建立主要是为了通过自监督学习,构建下一代工业级自动驾驶系统。
以前,自动驾驶主要依靠训练好的视觉感知模型进行学习。
这类车型使用大量数据进行标注,保证了自动驾驶的安全性,但其弊端也很明显。

自动驾驶系统将依赖于此,慢慢学习。
半监督和自监督学习通过大数据集挖掘大量未标记数据和少量未标记数据,可以提高学习的鲁棒性。
因此,建立足够大的数据集成为关键。
据悉,华为诺亚方舟实验室将基于这套训练集开启2D自动驾驶挑战赛。
最佳论文奖将被选出。
奖金丰厚,有兴趣的朋友或许可以一战成名。
延伸 · 阅读
- 2021-08-05 17:00荣耀50 Pro体验:首款骁龙778G在轻薄机身中拥有极快的充电效率
- 2021-08-05 17:00东方财富股票吧已经倒闭 部分地区仍然无法进入
- 2021-08-05 17:00微软确认存在另一个新的Windows后台打印程序安全漏洞
- 2021-08-05 17:00Xpeng Motors:2021年第二季度交付17398辆 同比增长439%
- 2021-08-05 17:00提高电气燃爆防御力 为人身安全再筑高墙
- 2021-08-05 17:00900万大学生失业?“平躺”是独立选择还是被迫无所事事?












