全球最大的多语言语音数据集现已开源!23种语言 超过40
最近,脸书开放了世界上最大的多语言语音数据集,之声:

这组数据涵盖了持续时间超过23种时间的40万,语。
其中,每种语言都有9000到18000小时的未标记语音数据。
此外,它还包括16种语言的1800小时转录语音数据和15种目标语言的17300小时翻译语音数据。
国外网友迅速称赞这一行为:
显然,如果数据集已经存在,就应该以道德的方式使用和改进它。
该数据集庞大的未标记数据量和广泛的语言覆盖范围对改进自我监控模型有很大帮助。
脸书还希望帮助提高语音数据集的质量和鲁棒性,并使语音转换神经网络的训练更加可靠。
最后,新的NLP系统开发加速,AI翻译效果越来越好。
数据集的名称,VoxPopuli的直译“人民的声音”也表明了其原始数据的来源——
所有来源的声音都来自2009年至2020年欧洲议会活动的录音。
十年欧洲会议文集
在欧洲议会的各种活动中,如全体会议、委员会会议和其他活动,发言者将轮流用不同的欧盟语言发言。
脸书刚刚从欧洲运动会官方网站上抢到了每场演讲的文字记录、演讲者信息和开始/结束时间戳。
然后,对所有原始语音数据进行处理,并将其大致分为以下三类:
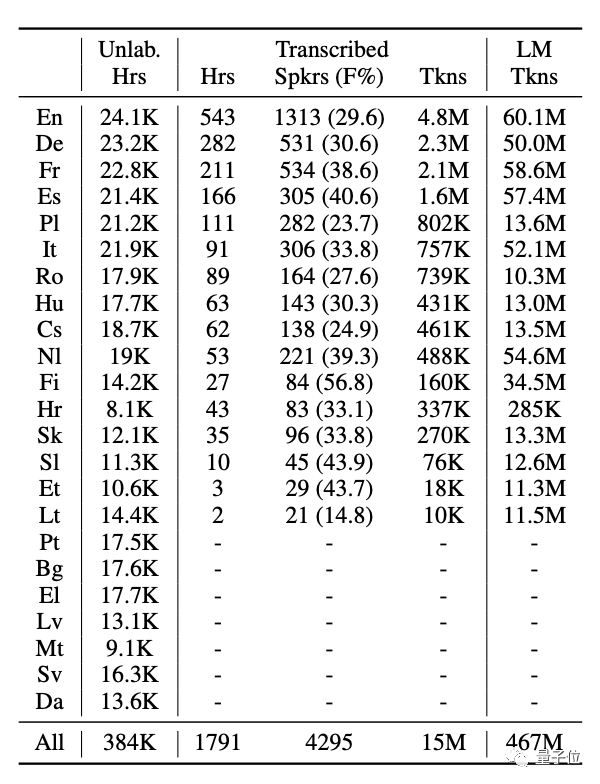
总共40万小时,无标签语音数据用23种语言
每种语言都有超过8000到20000个原始语音数据。
因此,脸书基于能量的语音活动检测(VAD)算法将完整的音频分成15-30秒的小段。
最后,获得没有太多数据不平衡和没有调整数据采样策略的数据集。
所以非常适合训练多语言模型。
除了未标记的数据,表中还有转录的语音数据,这是第二种类型:
总共1800个小时,转录语音数据用16种语言
虽然EC的官方时间戳可以用来定义会议中的发言人,但往往会被截断或与前后发言的片段混在一起,因此并不完全准确。
因此,脸书对全会音频采用了声纹分割聚类。
此时,语音片段的平均持续时间为197秒,然后使用语音识别(ASR)系统将其细分为大约20秒的短片段。
通过观察上表,我们可以看到最终的数据包含了很多属性,比如每种语言的时长、说话者的数量、女性说话者的百分比、分数等等。
15种目标语言的17,300小时口译语音数据:
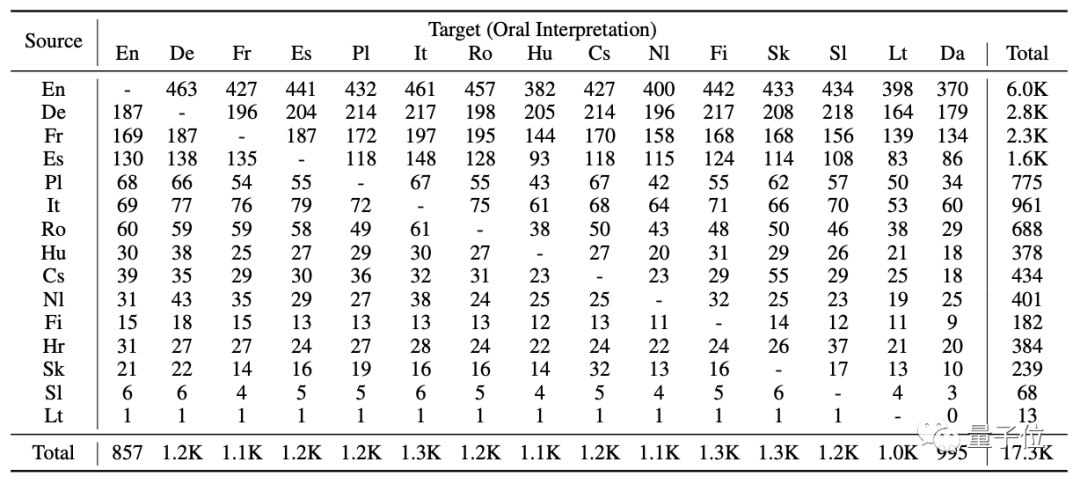
每个原话都有相应的同声传译,并且相互关联。
但是要使这个数据集可用,它必须经过大量的预处理和过滤。
因此,脸书使用语音识别(ASR)系统将源语音与目标语音在句子层面对齐。
它在域外环境中的半监督学习下是通用的
那么这个数据集是如何工作的呢?
第一步是对少样本的语音识别:使用无监督的预训练,包括域外语言
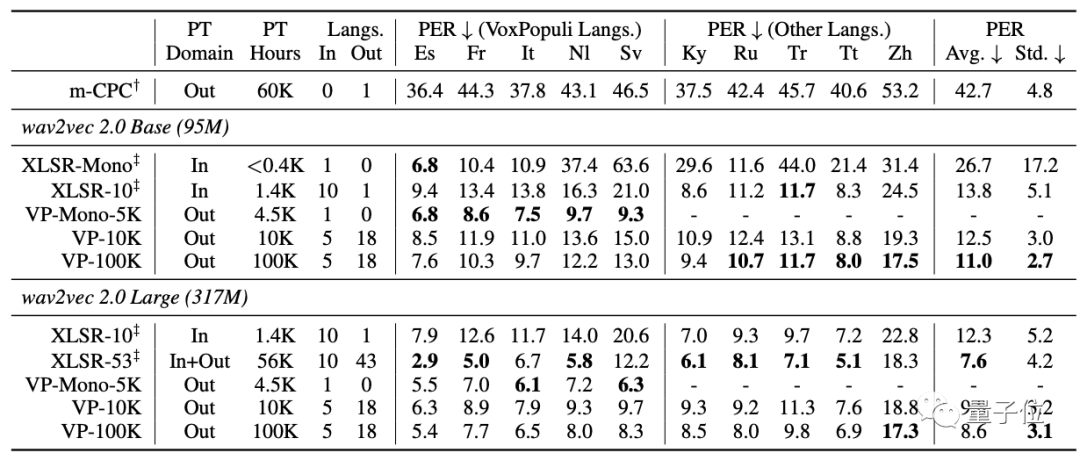
从表中可以看出,在五种VoxPopuli语言中,VP-Mono5K优于XLSR-Mono和XLSR-10。
而VP-100K在10种语言中有8种语言的性能优于XLSR-10。
再者,虽然XLSR-53覆盖了Zh语言,但在Zh上的性能远不如VP-100K(大)。
这表明VP-100K在语音表征上具有高度的通用性效应。
然后是使用VoxPopuli数据集的自训练或弱监督语言翻译(ST)和语音识别(ASR):
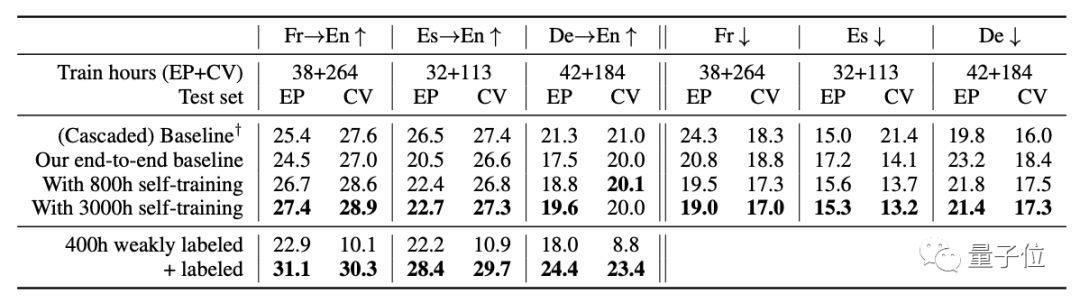
从表中可以看出,无论是对于域内语言还是域外语言,VoxPopuli的自训练在大多数情况下都能提高性能。
在翻译中,不需要添加昂贵的标签数据。
通过自我训练,可以缩小端到端模型和级联模型之间的差距。
论文地址:
http://arxiv.org/abs/2101.00390
下载:
http://github.com/facebookresearch/voxpopuli
参考链接:
[1]http://www .Reddit。com/r/机器学习/评论/owl 7g/n _脸书_ ai _ releases _ vox populi _ a _大规模/
[2]http://www .马克特波斯特。com/2021/08/02/脸书-ai-releases-vox populi-a-大规模-开放-多语言-语音-语料库人工智能翻译系统/
延伸 · 阅读
- 2021-08-06 16:37四川党建期刊集团藏地阳光全媒体中心用20种方言助力藏区
- 2021-08-06 16:37密码货币盗窃黑客返还2.6亿美元:想玩没钱
- 2021-08-06 16:37HaptX指责Meta抄袭其触觉手套的专利设计
- 2021-08-06 16:37《江西工人报》:走出"舒适区" 融入大格局
- 2021-08-06 16:37Shokz韶音运动耳机——颜值和科技感双在线
- 2021-08-06 16:37中国移动翼龙无人机在空中停留五小时:为河南受灾地区提供












