弹幕爆炸!OpenAI直播秀语音指令AI自动编程
金磊 梦晨 明敏 发自 凹非寺
量子位 报道
刚刚,OpenAI又上了一个新台阶。
只要输入自然句子,AI就会自动玩小游戏!
要点:不!用!你!编!程!
来,感受这种感觉。
第一步,“小人”可以通过输入一个单词使其根据方向键左右移动:
现在用左右箭头键控制它。
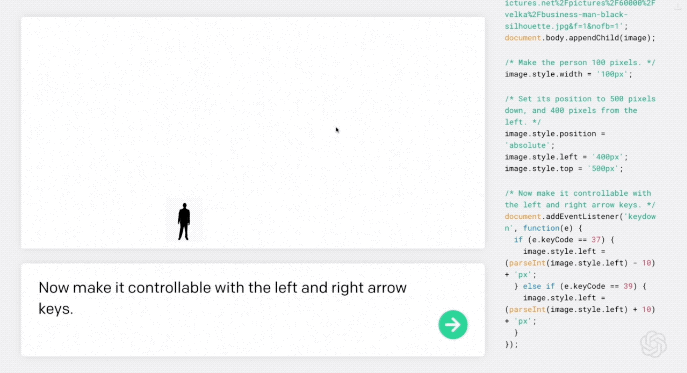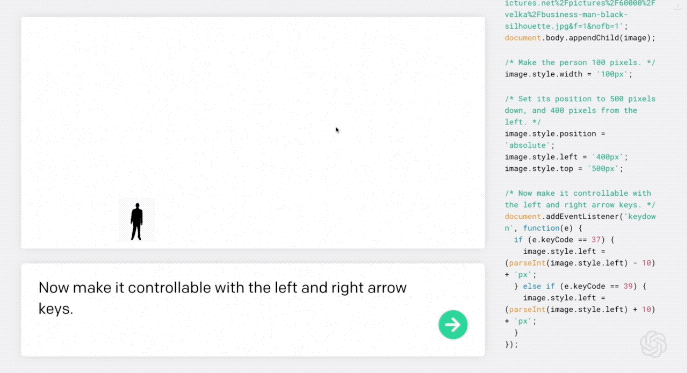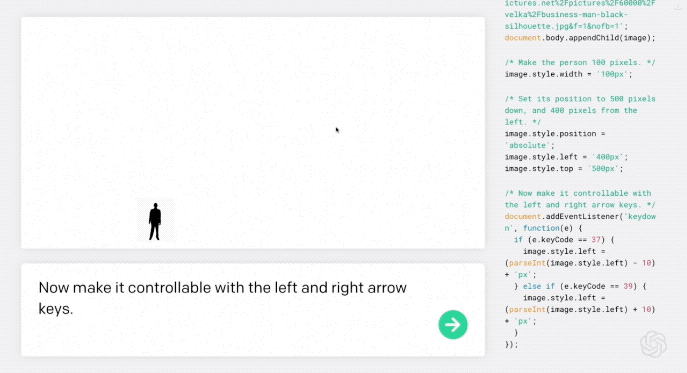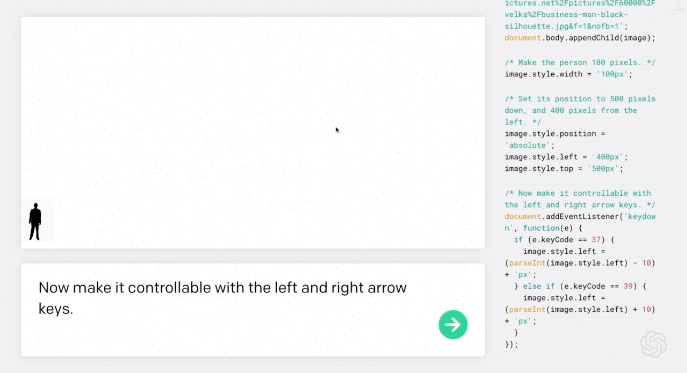
AI理解需求后,自动编程,然后小人就真的可以左右移动了。
第二步,将“石头”订婚,输入同一句话使其“从天而降”:
现在让它从天而降,并环绕。

第三步,简单的用自然语言制定一些规则,小个子被石头砸到就停止游戏。
不断检查人和巨石是否重叠,如果重叠,你就输了。

最后,让AI生成一个结束提示,应该包含一个鼓励的词。
AI选择了“再试一次!”
当然也有规则比较复杂的小游戏(比如加分数等功能),也可以用同样的方式分分钟生成:

这是魔法!现在小游戏的发展就靠“打字”了?
观看直播的观众也发出了同样的感慨,看着这满屏的弹幕:
有网友甚至高呼:
编程已经成为AI自己的游戏。

这是OpenAI发布的新产品——Codex,一款可以自己编程的AI。
人工智能编程并不是什么新鲜事,就像Copilot,不久前对GitHub大惊小怪一样。
但背后的技术其实来自于OpenAI。
然而,这一次,OpenAI将自己的能力提升到了一个新的水平。
不仅如此,玩一个小游戏只是Codex能力的冰山一角。
让我们体验一下它更惊艳的表现。
不要打字,直接语音命令吧!
为AI打“需求”还是有点麻烦。
你能直接说话发号施令吗?
这真的可以存在!
这次OpenAI与微软合作,制作了一个Word插件,带来了这个语音控制功能。
直接面对AI命令“去掉每行开头的空格”,AI通过微软给出的界面成功执行:

啪的一声,全文左对齐。
而且AI准确理解命令的含义,段与段之间的空行没有变化。
让我们做一些更复杂的事情。
给AI“五行加粗”的命令也很容易拿捏:
1D6AF5255D9D771D20969C157755F2339CEB809_size2207_w900_h509.gif" />这种把任务吩咐下去,就有“人”给你完成的感觉,是不是很像老员工指挥实习生?
总之呢,是比罗永浩前几年发布的TNT系统语音办公要强上那么“亿”点点了。
除了官方的演示,这次内测用户aniakubow,还让AI表演了通过152字描述生成一个网页。

可以看出这里Codex是用Javascript操作Document对象来生成网页,可能是训练集里没有直接的HTML代码的缘故吧。
最后,除了现场演示外,OpenAI还在Arxiv上发布了Codex的论文预印版。
论文中,Codex要面对的挑战甚至有刷IOI和ACM难度的竞赛题!
Codex用对每道题生成1000种答案这种暴力方法,能做出600多道竞赛题测试集中的3.23%,并且通过全部的测试用例。
这个编程题目测试集是UC伯克利研究人员在5月份刚刚做好的。
当时测试的GPT-2、GPT-3和开源的GPT-Neo可是在竞赛难度上全军覆没,一道都没做出来。
没想到短短两个多月,专为代码而生的Codex就为前辈们洗刷了耻辱。
Codex的“魔法”,是如何实现的?
这么炫酷的能力,莫非还是像GPT-3一样堆数据,大力出奇迹吗?
不全是,这次Codex最大的一个版本是120亿参数,比起GPT-3的1750亿还是小了很多。
要了解具体情况,还要从它的开发历程说起。
最早,OpenAI研究人员拿GPT-3做各种试验,发现GPT-3能从Python注释中生成一些简单的代码。
这可把他们高兴坏了,因为GPT-3根本没特意拿代码训练过,只是看过一些博客和帖子中零星的代码片段。
想想GPT-3在自然语言上的出色表现,要是专门训练一个代码版的GPT-3,那肯定也能再次震惊业界。
于是,他们找到了GitHub,这个拥有最多开源代码的“小伙伴”来合作。
一开始是拿到了179G的Python代码,但其中不乏存在一些篇幅太长的,以及明显是自动生成的那种。
在剔除掉这些“不达标”的代码后,最后留下的代码大小为159G。
接下来当然是做预训练,把这些代码都喂给AI (Codex)。
不过这里有一个问题:
GitHub上的开源代码难免会有Bug,AI学了一堆有问题的代码可咋办?
其实这倒也好说,预训练之后不是还要微调嘛。
微调的时候,全用编程竞赛里的正确答案,以及PyPI里的靠谱开源代码就可以了。
最后,120亿参数版的Codex,能对28.81%的问题给出正确答案。
这个准确率超过之前的开源代码预训练模型GPT-Neo和GPT-J,还有基于GPT-2的代码补全工具TabNine。
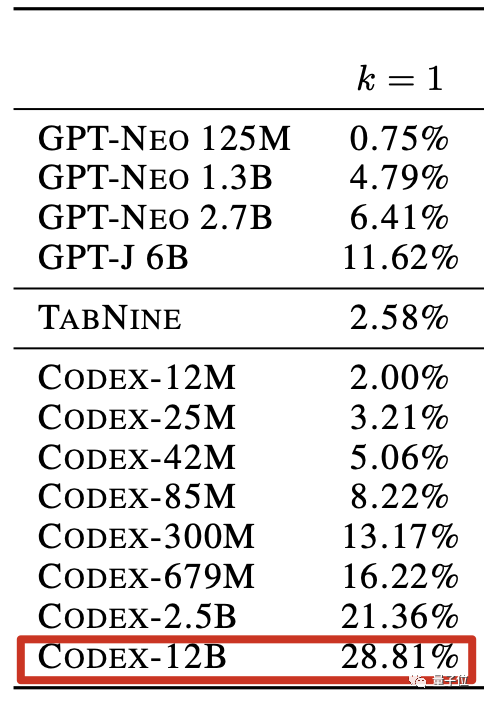
这个成绩虽然不错,不过离能实际应用还是有点远了。
不过,这也难不住OpenAI的研究团队。
他们很快便想到了“突破口”:
人类编程的时候,不也经常先出一个版本,然后反复修改bug嘛~
那就让AI像人一样反复修改,改出100个版本来,从中总能挑出几个正确的来。
用上这种拿“量”堆出来的方法,Codex的最终成绩是:
77.5%!
强,但不完全强
Codex令人惊艳的表现,一度让网友们大呼:
要失业了要失业了!
有人直接在公屏上打出:再见了,计算机专业的学子们。

不过大家也不必如此担心,因为在演示过程中,其实就出现了翻车的情况。

在输入“Say Hello World with empathy”后,Codex给出的结果居然还是“Hello World with empathy”。
这也侧面说明了Codex现在还不是完美的。
OpenAI就表示:
即便是参数达到120亿的Codex 12B,它的能力可能也还不如一位编程刚刚入门的学生。
虽然Codex学习上亿行代码,但它更大程度是“记住了”这些代码,并不是真正意义上的懂编程语言。
而且Codex对长字符串的理解也比较困难。
并且随着字符数量的增加,Codex的性能表现下降得非常明显。
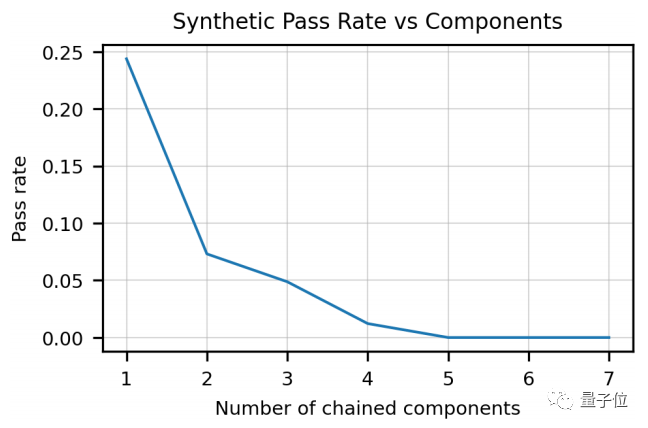
在这种情况下,Codex就不能很好地理解用户的意图,结果可想而知,给出的代码可能就是完全错误的了。
此外,在理解变量和运算较多的注释时,Codex也会犯错:

在这个例子中,120亿参数版的Codex,忘记了对变量w做减法,也没有返回所有数字的乘积。
这些对于还在学习编程的新手程序员而言,非常不友好。
而且由于生成的代码准确性和正确性都还不能保证,因此在安全问题上也存在一定风险。
不仅如此,OpenAI还表示,Codex会生成带有种族歧视的内容。
在社会层面上,OpenAI还提出Codex的出现或许会冲击程序员的就业;如果被滥用,还有网络犯罪方面的隐患。
最后还有一点,就是环境方面的问题。
毕竟它作为大模型,参数量的规模不容小觑。
要不是合作方微软Azure云买了足够多的碳排放限度,Codex可能还不能和我们见面呢(手动狗头)。
延伸 · 阅读
- 2021-08-11 17:11“彤心锁汇,蝶变青春”汇泰龙品牌战略及新VI形象发布暨代言人发布会盛大召开!
- 2021-08-11 17:11腾讯《QQ堂》宣布将于2022年4月20日停止运营 已经上线17年了
- 2021-08-11 17:11BitTorrent庆祝20岁生日:是时候重新审视这场文件共享革命了
- 2021-08-11 17:11徐明星拟申请清算和解散 OKCoin曾经说过他会把公司捐给国家
- 2021-08-11 17:11跨国车企再获“独资”:沃尔沃收江铃重卡7.8亿元
- 2021-08-11 17:11原果萃取,清爽出圈!初饮NFC果汁,匠心产品引新潮!












