马斯克:视觉神经网络实现的自动驾驶安全性比人类高十几倍
记者| 邵文
9月17日上午,在海南海口举行的2021世界新能源汽车大会上,特斯拉CEO埃隆马斯克在视频演讲中表示,未来的自动驾驶可以通过视觉神经网络实现,比普通人安全十几倍。

近日,特斯拉向其抢先体验团队推出了FSD(全自动驾驶)Beta V10软件。这是全新版本的纯视觉自动驾驶方案,在特斯拉AI日发布最新的应用于自动驾驶的视觉神经网络后,做出了重要的技术改进。
特斯拉CEO埃隆马斯克表示,预计将于9月25日左右向所有特斯拉车主开放。
FSD Beta 10的软件版本号为2021.24.15。在这个版本软件的支持下,特斯拉几乎可以在高速公路和城市街道上行驶,但它仍然被认为是L2的驾驶员辅助驾驶,因为它要求驾驶员对车辆保持负责,把手放在方向盘上,随时准备控制。
根据参与测试的用户在Youtube上发布的针对性测试和路测结果(翻译为“油管”,目前全球最大的视频搜索和分享平台),仍有很多场景会出现问题。其中最明显的改进就是驾驶时的可视化用户界面,越来越多的路标和交通标志正在被细分识别,但有些路标仍然无法被准确识别。
在最近的特斯拉人工智能日,特斯拉AI负责人Andrej Karpathy和自动驾驶硬件高级总监Ganesh Venkataramanan介绍了纯视觉自动驾驶系统和FSD软件的最新成果。在此之前,5月,马斯克发文称,特斯拉最新版本FSD将取消毫米波雷达,采用纯视觉感知方案。
在自动驾驶感知领域,有两种截然不同的路径:——纯视觉学校和激光雷达学校。纯视觉派认为自动驾驶所需要的周围环境感知,只有依靠摄像头才能实现。特斯拉、氪星、百度都采用纯视觉感知方案。激光雷达学校以激光雷达为主导,配合毫米波雷达、超声波传感器、摄像头多传感器,实现周边环境感知。商汤的AR小巴、小鹏的P5、蔚来的ET7都采用了激光雷达方案。
商汤智能驾驶R&D总监李益康在接受《The Paper》采访时表示,“无论是纯视觉还是多传感器融合,最终都有可能实现L4或L5级别的自动驾驶。不同的是,激光雷达的引入实际上简化了问题,因为我们引入了很多额外的信息,这些信息是视觉的补充,一些信息,比如深度,是可以准确估计的。如果最后两条路线能够实现L5级自动驾驶,相信多传感器融合的路线可能会更快。当然,感知只是决定自动驾驶能否实现的因素之一。”
特斯拉“纯视觉派”技术路线:视觉神经网络
特斯拉人工智能和自动驾驶视觉总监Andrej Karpathy认为,将激光雷达加入自动驾驶堆栈会带来自身的复杂性。在CVPR 2021自动驾驶研讨会上,Karpathy说:“你必须提前用激光雷达绘制一张环境地图,然后你必须创建一张高清地图。您必须插入所有车道及其连接模式和所有交通灯。收集、构建和维护这些高清激光雷达地图是不可扩展的,要让这一基础设施保持最新将是极其困难的。”
Karpathy表示,特斯拉在自动驾驶堆栈中不使用激光雷达和高清地图。“所有发生的事情都是第一次在车里,这是基于车周围8个摄像头的视频。”。
特斯拉安装了8个摄像头,没有深度信息。他们的目标之一是形成向量空间视图。那么你怎么知道下一辆车在哪里,还有多长时间?
第一个难点是,不同视角的摄像头只能看到周围环境的一部分,标定、位置、视角方向都不一样。比如下图,谁能知道这个点在相机视图中对应的是哪个点?只有当我们知道这些信息,我们才能准确地将周围的物体放在向量空间视图中。
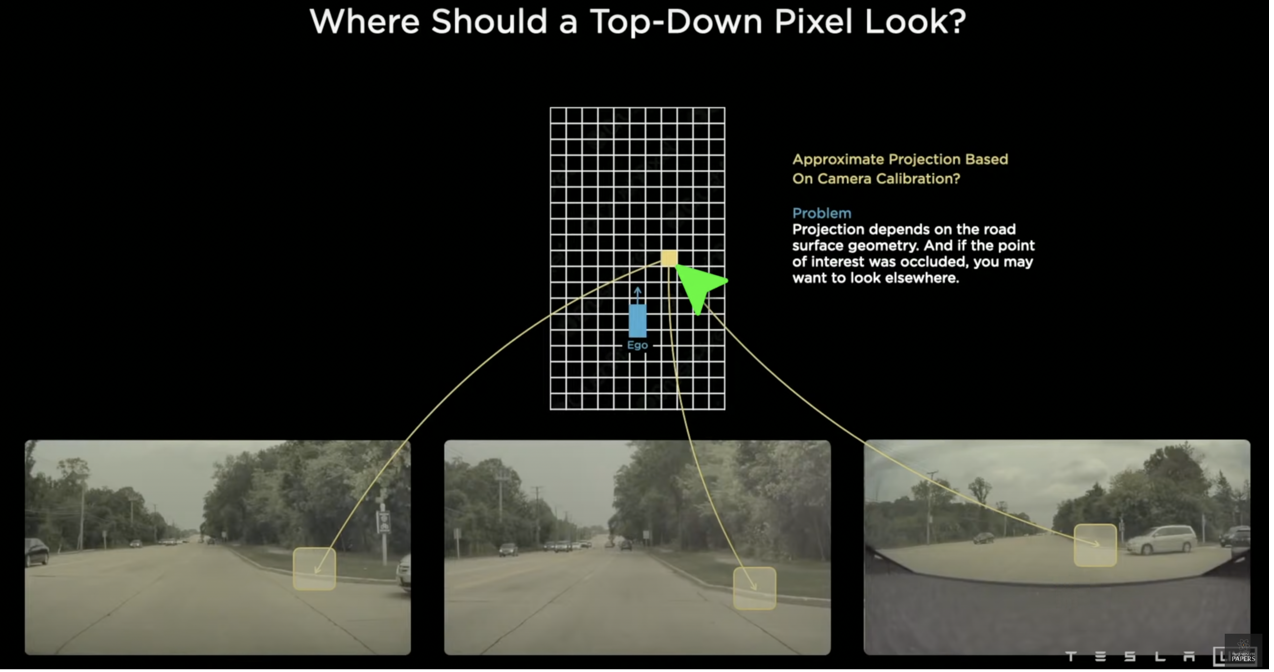
因此,需要一种集成来自多个摄像机的信息的技术。特斯拉使用的是2017年提出的Transformer神经网络,目前已经席卷了自然语言处理和计算机视觉领域。
然后,加入带有时间概念的RNN(递归神经网络)来判断运动物体的速度,并预测遮挡物体。
测。RNN体现了“人的认知是基于过往的经验和记忆”的观点,通过记忆来处理任意时序的输入序列,从而对接下来要发生的事情进行预测。比如这里对被遮挡物预测,通过对遮挡前的特征和轨迹的记忆,使得视野被短暂遮蔽的情况下,依然可以预测遮挡视野后的物体运动轨迹,并记录已行驶过的路段的各种路标。而对于深度信息,在缺少了雷达信息后,则需要通过对大量的有深度标注的相机数据进行训练得到的检测算法来得到。
激光雷达多传感器融合方案
激光雷达多传感器方案是以激光雷达为主导,毫米波雷达、超声波传感器及摄像头作为辅助。通过激光雷达发射激光束,测量激光在发射及收回过程其中的时间差、相位差,从而确定车与物体之间的相对距离,实现环境实时感知及避障功能。摄像头的价格在几十美元左右,而激光雷达则要昂贵的多,这或许也是很多纯视觉流派厂商一个没有说的难言之隐。
商汤智能驾驶研发总监李怡康向澎湃新闻介绍,“我们会做很多种传感器的评测,去找到最适合我们设计需求的传感器方案,然后通过自动化的算法将这些传感器摆放到最合适的地方,从而实现最优的环境信息获取。传感器之间是不在一个坐标系下的,我们通过自动化标定算法将不同传感器的特性及相关关系非常准确地找出来,然后设计融合感知模型,并用大量的感知数据去训练它,最终实现多传感器融合感知。”
自动驾驶底层逻辑是感知、决策、执行三个步骤的结合,对周围环境的周密感知是所有决策的基础,也是自动驾驶汽车的安全保障。在了解周围环境中物体的位置、速度和方向、路面的性质、路缘石的位置、信号(交通、道路标志)等之后,自动驾驶系统则要开始做计划和控制:首先是其他移动物体在接下来的短时间会做什么,然后是根据整体计划(比如规划的通向目的地路线)计划自己要做什么,最后就是告诉汽车要做什么。
延伸 · 阅读
- 2021-09-17 16:45鸿蒙不支持快充吗?华为:充电器是山寨产品 建议买华为
- 2021-09-17 16:45iPhone 12采用新的WiFi标准或是为了与苹果智能眼镜兼容
- 2021-09-17 16:45房地产跨境进入?《ZTO快报》怒斥2亿成立房地产公司 副
- 2021-09-17 16:45《海南日报》推创意H5 秉持"马拉松"精神到达理想彼岸
- 2021-09-17 16:45据说JD.COM程序员迫于巨大压力 在代码中加入了“脏话”
- 2021-09-17 16:45用领先智慧水务解决方案 树合作共赢之行业典范












